目标
获取快手视频点赞数、评论数、 播放数
分析视频接口
https://m.gifshow.com/fw/photo/5232901352181146092

请求头:
1
2
3
4
5
6
7
8
9
10
11
12
13
| sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="98", "Google Chrome";v="98"
sec-ch-ua-mobile: ?1
sec-ch-ua-platform: "Android"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Mobile Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*
|
响应(关键信息 window.pageData=):略
互动量相关 JSON.obfuseData:
1
2
3
4
5
6
7
8
| {
"id": 263,
"fontCdnUrl": "https://tx2.a.kwimgs.com/kos/nlav10312/mdata/pkg/kwai-font/fontscn_263f9585.ttf",
"fontCdnStyle": "<style>\n @font-face {\n font-family: kwaiFont;\n src: url(https://tx2.a.kwimgs.com/kos/nlav10312/mdata/pkg/kwai-font/fontscn_263f9585.ttf) format(\"truetype\");\n }\n .font {\n font-family: \"kwaiFont\";\n font-style: normal;\n font-weight: normal;\n font-variant: normal;\n text-transform: none;\n line-height: 1;\n -webkit-font-smoothing: antialiased;\n }\n </style>",
"commentCount": "<SPAN STYLE='FONT-FAMILY: kwaiFont;'></SPAN>",
"likeCount": "<SPAN STYLE='FONT-FAMILY: kwaiFont;'></SPAN>",
"viewCount": "<SPAN STYLE='FONT-FAMILY: kwaiFont;'></SPAN>"
}
|
页面中显示:
1
| <p class="video-like"> <span style="FONT-FAMILY: kwaiFont;"></span> </p>
|
可以明显看出是有字体反爬处理,需要下载字体文件进行解密
什么是字体反爬?
使用自定义的 ttf 文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容
字体反爬实现原理
厂商会随机生成成千上万套字库,并且保存好编码、字库文件、字的映射关系。文章显示的时候会从库中随机查询一套字库,并把文章中的替换成 unicode 编码,以达到字体加密的效果。
字体反爬的前世今生
初级难度:一套字体做加密
做好映射解密即可
中级难度:生成多套字体和编码
比如:猫眼电影,58 同城等等,汽车之家
虽然生成了多套,但是每个字对应的字体信息是不变
比如一个字的笔画数,和 x,y 变化都很小,可以利用这个特征解析字体的 xml 文件,做特征映射
高级难度:字体变形,字体信息随机化
比如:快手
静态字体解密
下载字体用 FontCeator 打开

将字体文件转为 xml
先用 FontCreator 将字体转为 woff 文件,再用 python 转为 xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <GlyphID id="0" name=".notdef"/>
<GlyphID id="1" name="uniEAC6"/>
<GlyphID id="2" name="uniEC96"/>
<GlyphID id="3" name="uniF38C"/>
<GlyphID id="4" name="uniF088"/>
<GlyphID id="5" name="uniEC7E"/>
<GlyphID id="6" name="uniF5D6"/>
<GlyphID id="7" name="uniF20E"/>
<GlyphID id="8" name="uniF7A6"/>
<GlyphID id="9" name="uniF5B9"/>
<GlyphID id="10" name="uniE9D5"/>
<GlyphID id="11" name="uniE43E"/>
<GlyphID id="12" name="uniE729"/>
<GlyphID id="13" name="uniE47F"/>
<GlyphID id="14" name="uniE7CA"/>
<GlyphID id="15" name="uniF6C7"/>
|
注意:这个 xml 表示的是 id 和值的映射关系。比如
uniE43E 字体对应真实的值:4 , 对应的 glyph11
查看字体解密规则
1
| "commentCount": "<SPAN STYLE='FONT-FAMILY: kwaiFont;'></SPAN>",
|
规则:&#+16 进制加上;号
解密
逆推字体加密
将字体的 key 转为 16 进制,&#+16 进制与加密的对比,得到对应的值
1
2
3
4
5
| [ #编写对应的列表
'w', '5', 'm', 'k', '6', '.', '1', '3', '+', '0', '4', '8', '9',
'7', '2'
]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| fontCdnUrl = "https://tx2.a.kwimgs.com/kos/nlav10312/mdata/pkg/kwai-font/fontscn_263f9585.ttf"
key_map = {}
font_content = requests.get(fontCdnUrl).content
font = TTFont(BytesIO(font_content))
code = font.getGlyphOrder()[1:]
nums = [
'w', '5', 'm', 'k', '6', '.', '1', '3', '+', '0', '4', '8', '9',
'7', '2'
]
temp = dict(zip(code, nums))
res = font.getBestCmap()
for k, v in res.items(): #解析字体
print("字体的原始:" +str(k))
kk = str(hex(k))
print("字体的转换成16进制:" + str(kk))
kk = kk[1:]
print("去除前缀:" + str(kk))
kk ='&#' + kk
print("拼接&#得到最后加密的:" + str(kk))
print(str(v)+"字体对应真实的值:" + str(temp[v]))
key_map[kk] = temp[v]
re_html_code = re.compile(r'&#x[\da-f]{4}')
text = "" #7751confusionLikeCount=
words = re_html_code.findall(text)
result = ''.join(key_map[i] for i in words)
print(result)
|
得到 7762, 静态字体破解搞定~
动态字体解密
每次请求的字体都不一样


可以发现字体的形状不同,无法通过笔画来映射
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| <pt x="-10158" y="550" on="1"/>
<pt x="-10154" y="545" on="0"/>
<pt x="-10161" y="534" on="1"/>
<pt x="-10160" y="350" on="0"/>
<pt x="-10490" y="54" on="1"/>
<pt x="-10492" y="27" on="1"/>
<pt x="-10492" y="5" on="1"/>
<pt x="-10285" y="0" on="1"/>
<pt x="-10156" y="4" on="1"/>
<pt x="-10031" y="-5" on="1"/>
<pt x="-10035" y="16" on="1"/>
<pt x="-10029" y="58" on="1"/>
<pt x="-10034" y="87" on="1"/>
<pt x="-10232" y="75" on="1"/>
<pt x="-10236" y="87" on="1"/>
<pt x="-10256" y="83" on="0"/>
<pt x="-10300" y="83" on="1"/>
<pt x="-10323" y="77" on="0"/>
<pt x="-10356" y="78" on="1"/>
<pt x="-10116" y="306" on="0"/>
<pt x="-10077" y="472" on="1"/>
<pt x="-10071" y="499" on="0"/>
<pt x="-10066" y="529" on="1"/>
<pt x="-10070" y="610" on="0"/>
<pt x="-10110" y="665" on="1"/>
<pt x="-10119" y="688" on="0"/>
<pt x="-10124" y="692" on="1"/>
<pt x="-10156" y="716" on="0"/>
<pt x="-10201" y="737" on="1"/>
<pt x="-10237" y="742" on="0"/>
<pt x="-10282" y="743" on="1"/>
<pt x="-10394" y="740" on="0"/>
<pt x="-10497" y="632" on="1"/>
<pt x="-10442" y="594" on="1"/>
<pt x="-10441" y="592" on="1"/>
<pt x="-10372" y="671" on="0"/>
<pt x="-10293" y="672" on="1"/>
<pt x="-10226" y="677" on="0"/>
<pt x="-10191" y="630" on="1"/>
<pt x="-10163" y="603" on="0"/>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| <pt x="-9192" y="740" on="0"/>
<pt x="-9129" y="740" on="1"/>
<pt x="-9114" y="755" on="0"/>
<pt x="-9099" y="746" on="1"/>
<pt x="-9037" y="747" on="0"/>
<pt x="-8991" y="706" on="1"/>
<pt x="-8986" y="698" on="0"/>
<pt x="-8973" y="696" on="1"/>
<pt x="-8973" y="695" on="0"/>
<pt x="-8975" y="695" on="1"/>
<pt x="-8917" y="624" on="0"/>
<pt x="-8920" y="525" on="1"/>
<pt x="-8920" y="337" on="0"/>
<pt x="-9203" y="69" on="1"/>
<pt x="-9180" y="74" on="0"/>
<pt x="-9159" y="75" on="1"/>
<pt x="-9102" y="79" on="0"/>
<pt x="-9086" y="83" on="1"/>
<pt x="-9016" y="81" on="1"/>
<pt x="-8878" y="77" on="1"/>
<pt x="-8881" y="66" on="1"/>
<pt x="-8882" y="13" on="1"/>
<pt x="-8881" y="-3" on="1"/>
<pt x="-8917" y="-1" on="1"/>
<pt x="-9346" y="2" on="1"/>
<pt x="-9340" y="50" on="1"/>
<pt x="-9345" y="58" on="1"/>
<pt x="-9008" y="348" on="0"/>
<pt x="-9006" y="534" on="1"/>
<pt x="-9003" y="552" on="0"/>
<pt x="-9008" y="574" on="1"/>
<pt x="-9016" y="607" on="0"/>
<pt x="-9036" y="635" on="1"/>
<pt x="-9049" y="639" on="0"/>
<pt x="-9063" y="648" on="1"/>
<pt x="-9072" y="660" on="0"/>
<pt x="-9080" y="658" on="1"/>
<pt x="-9077" y="662" on="0"/>
<pt x="-9083" y="669" on="1"/>
<pt x="-9107" y="671" on="0"/>
<pt x="-9144" y="676" on="1"/>
<pt x="-9163" y="678" on="0"/>
<pt x="-9187" y="672" on="1"/>
<pt x="-9206" y="651" on="0"/>
<pt x="-9229" y="648" on="1"/>
<pt x="-9263" y="626" on="0"/>
<pt x="-9293" y="586" on="1"/>
<pt x="-9314" y="600" on="1"/>
<pt x="-9326" y="628" on="1"/>
<pt x="-9349" y="639" on="1"/>
<pt x="-9304" y="686" on="0"/>
<pt x="-9259" y="716" on="1"/>
<pt x="-9251" y="717" on="0"/>
<pt x="-9242" y="719" on="1"/>
|
经过下载多个字体文件查看,发现如下:
- 每次请求都是不同的字体,字体库不是简单的几套
- 笔画数不同
- x,y 坐标不同,并且移动很大
所以无法通过解析字体的 xml 利用有规律的特征来做映射
思路一:
将获取到的加密字段自己组装成 html 显示后,截图,ocr 识别出来
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| <style>
@font-face {
font-family: kwaiFont;
src: url(https://tx2.a.kwimgs.com/kos/nlav10312/mdata/pkg/kwai-font/fontscn_28789ff8.ttf)
format("truetype");
}
.font {
font-family: "kwaiFont";
font-style: normal;
font-weight: normal;
font-variant: normal;
text-transform: none;
line-height: 1;
-webkit-font-smoothing: antialiased;
}
</style>
<div>
<span STYLE="FONT-FAMILY: kwaiFont;"></span>
</div>
|

保存为 html
略
截图
略
OCR 识别
略
思路二
将字体文件字体分割为 png,ocr 识别成出来。放入集合按顺序排列
下载安装 tesseract-ocr
下载语言包
https://tesseract-ocr.github.io/tessdoc/Data-Files
放入 Tesseract-OCR\tessdata
配置环境变量
将字体切割成图片代码
1
2
3
4
5
6
7
8
| def uni_2_png_stream(txt, font, img_size=512): """将字形转化为图片流 Args: txt
([type]): [description] font ([type]): [description] img_size (int, optional):
[description]. Defaults to 512. Returns: [type]: [description] """ img =
Image.new('1', (img_size, img_size), 255) draw = ImageDraw.Draw(img) font =
ImageFont.truetype(font, int(img_size * 0.7)) txt = chr(txt) x, y =
draw.textsize(txt, font=font) draw.text(((img_size - x) // 2, (img_size - y) //
2), txt, font=font, fill=0) # draw.text((0,0), txt, font=font, fill=0) return
img
|
对比 ocr 效果
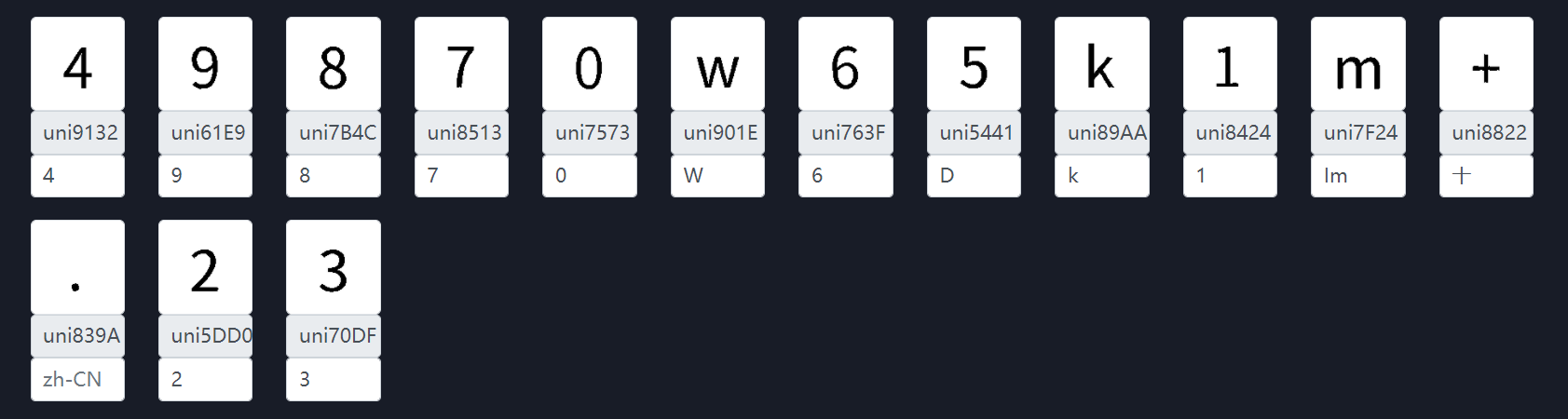
uniE43E 字体对应真实的值:4
uniE47F 字体对应真实的值:9
uniE729 字体对应真实的值:8
uniE7CA 字体对应真实的值:7
uniE9D5 字体对应真实的值:0
uniEAC6 字体对应真实的值:w
uniEC7E 字体对应真实的值:6
uniEC96 字体对应真实的值:D
uniF088 字体对应真实的值:k
uniF20E 字体对应真实的值:1
uniF38C 字体对应真实的值:m
uniF5B9 字体对应真实的值:+
uniF5D6 字体对应真实的值:.
uniF6C7 字体对应真实的值:2
uniF7A6 字体对应真实的值:3
可以看出来识别率 90%,数字 5 识别成 D 了。
优化数字识别率 和 ocr 执行时间
1
2
3
4
| pytesseract.pytesseract.tesseract_cmd = filename # text =
pytesseract.image_to_string(image, lang='chi_sim', config='--psm 10') # 注意
这里替换语言库,提升纯数字识别准确率 和 执行时间 11秒 提升到6秒 text =
pytesseract.image_to_string(image, config='--psm 10')
|
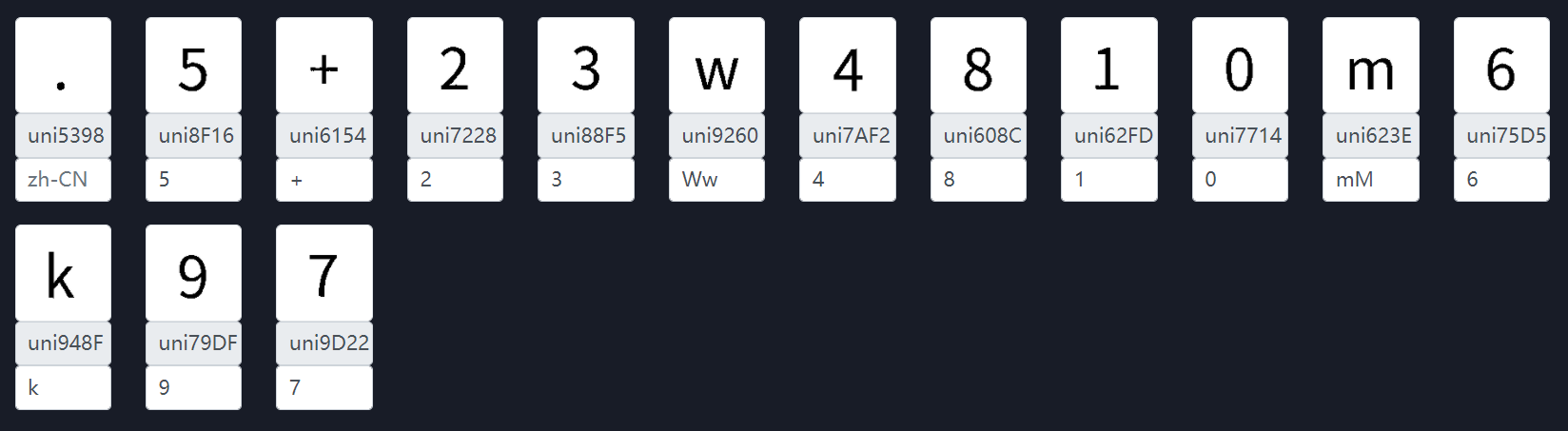
测试了几个 font 文件,数字识别率 100%
继续优化
tesseract:
nums:[‘Ww’, ‘+’, ‘4’, ‘9’, ‘2’, ‘6’, ‘mM’, ‘8’, ‘’, ‘7’, ‘3’, ‘k’, ‘5’, ‘0’, ‘1’]
INFO: 127.0.0.1:2629 - “GET /api/ks_interactive_data/3xdyxk622whqx2q HTTP/1.1” 200 OK
2022-03-01 12:28:14.721 | WARNING | utils:ocr_processor:146 - 识别耗时:2227.240800857544
2022-03-01 12:28:14.722 | WARNING | main:request:123 - result:0_2_65
2022-03-01 12:28:14.723 | WARNING | main:request:124 - 耗时:3415.691375732422
更换 ocr 识别后:
2022-03-01 12:31:36.279 | WARNING | utils:ocr_processor:146 - 识别耗时:131.30450248718262
nums:[‘’, ‘7’, ‘w’, ‘2’, ‘0’, ‘9’, ‘6’, ‘3’, ‘十’, ‘4’, ‘8’, ‘5’, ‘k’, ‘1’, ‘m’]
INFO: 127.0.0.1:2923 - “GET /api/ks_interactive_data/3xdyxk622whqx2q HTTP/1.1” 200 OK
2022-03-01 12:31:36.290 | WARNING | main:request:123 - result:0_2_65
2022-03-01 12:31:36.290 | WARNING | main:request:124 - 耗时:1669.9013710021973
DID 风控解决
待下篇分解
大规模测试:
10 个线程,单 IP,5 个小时一共跑了 62264 次,失败次数 3266,成功率 94%
平均一个小时 12452 次。
单个请求 2 秒以内完成。1 秒 4 和 1 秒 8 居多,通过 redis 预存 did 的话,可以进一步提升耗时到 1 秒以内。
警告:仅供学习和参考,不可用于非法用途!